Samsung Electronics представила TRUEBench – собственный бенчмарк для оценки продуктивности ИИ
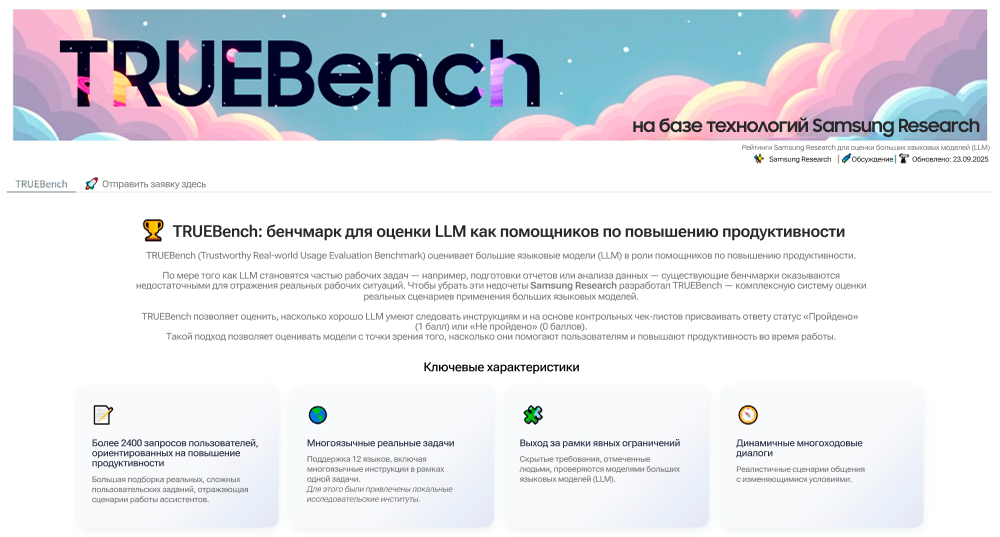
Компания Samsung Electronics представила TRUEBench (Trustworthy Real-world Usage Evaluation Benchmark) — собственную методику, разработанную Samsung Research для оценки продуктивности искусственного интеллекта.
TRUEBench включает комплексный набор показателей, позволяющих измерять, как большие языковые модели (LLM) справляются с реальными задачами по повышению продуктивности на рабочем месте. Для максимальной объективности TRUEBench учитывает разнообразные сценарии диалогов и поддержку нескольких языков.
Опираясь на собственный опыт компании Samsung по использовании ИИ для повышения продуктивности, TRUEBench оценивает наиболее распространенные корпоративные задачи — такие как генерация контента, анализ данных, суммаризация и перевод — в рамках 10 категорий и 46 подкатегорий. Для обеспечения объективности результатов используется автоматическая оценка на базе ИИ, основанная на критериях, которые разрабатываются и уточняются совместно с человеком и искусственным интеллектом.
«Samsung Research обладает глубокими знаниями и конкурентными преимуществами благодаря опыту применения ИИ в реальных условиях», — отметил Пол Чон (Paul Kyungwhoon Cheun), технический директор DX Division и руководитель Samsung Research. — «Мы ожидаем, что TRUEBench станет новым стандартом оценки продуктивности в индустрии и поможет Samsung Electronics укрепить свое технологическое лидерство».
С ростом применения ИИ для рабочих задач все больше компаний проявляют интерес к измерению продуктивности LLM–моделей, однако существующие бенчмарки в основном ориентированы на оценку общей производительности, сосредоточены преимущественно на английском языке и ограничиваются структурой «вопрос–ответ». Это мешает им полноценно отражать реальные рабочие ситуации.
Чтобы преодолеть эти ограничения, TRUEBench включает 2485 тестовых наборов по 10 категориям и 12 языкам[1], а также поддерживает кросс-лингвистические сценарии. Такие тесты помогают понять, какие задачи действительно по силам ИИ–моделям — от коротких запросов длиной 8 символов до обработки больших текстов более 20000 символов, включая создание кратких изложений документов.
Для оценки работы моделей ИИ важно иметь четкие критерии оценивания правильности ответов. В реальных условиях не все намерения пользователей формулируются напрямую. TRUEBench обеспечивает более реалистичную проверку, учитывая не только точность ответа, но и соответствие скрытым ожиданиям пользователя.
В Samsung Research критерии оценки формируются в результате совместной работы человека и ИИ. Сначала их задают специалисты-аннотаторы, затем ИИ проверяет на наличие ошибок, противоречий или лишних ограничений. После этого критерии снова дорабатываются человеком. Так процесс повторяется до достижения максимальной точности. На основе таких перекрестно проверенных критериев проводится автоматическая проверка ИИ–моделей, что минимизирует субъективность и обеспечивает надежность результатов. Более того, для успешного прохождения теста модель должна выполнить все условия — это делает оценку более детализированной и точной.
Образцы данных и рейтинги TRUEBench размещены на глобальной open-source платформе Hugging Face. Пользователи могут сравнивать до пяти моделей одновременно и быстро получать комплексное представление об их производительности. Также публикуются данные о средней длине ответов, что позволяет одновременно оценивать и качество, и эффективность работы моделей. Подробная информация доступна на странице TRUEBench в Hugging Face.
[1] Китайский, английский, французский, немецкий, итальянский, японский, корейский, польский, португальский, русский, испанский и вьетнамский.
Новости компании > Технологии
По любым вопросам, связанным с сервисным обслуживанием, пожалуйста, обращайтесь на сайт samsung.com/ru/support.
По вопросам сотрудничества со СМИ, пожалуйста, пишите на samsung@maslov.agency.